3 R-Einführung
lavaanGUI basiert auf der Sprache des Statistikprogramms R. Auch wenn ihr bei der Verwendung von lavaanGUI nur sehr wenig dieser Sprache verwenden müsst, ist es doch hilfreich für das Verständnis einige Dinge über die Anwendung und Verwendung der Sprache zu wissen. Wollt ihr allerdings direkt mehr über die Verwendung der lavaanGUI erfahren, könnt ihr dieses Kapitel auch erstmal überspringen.
Öffnet man RStudio, sieht man es in vier verschiedene Fenster unterteilt.
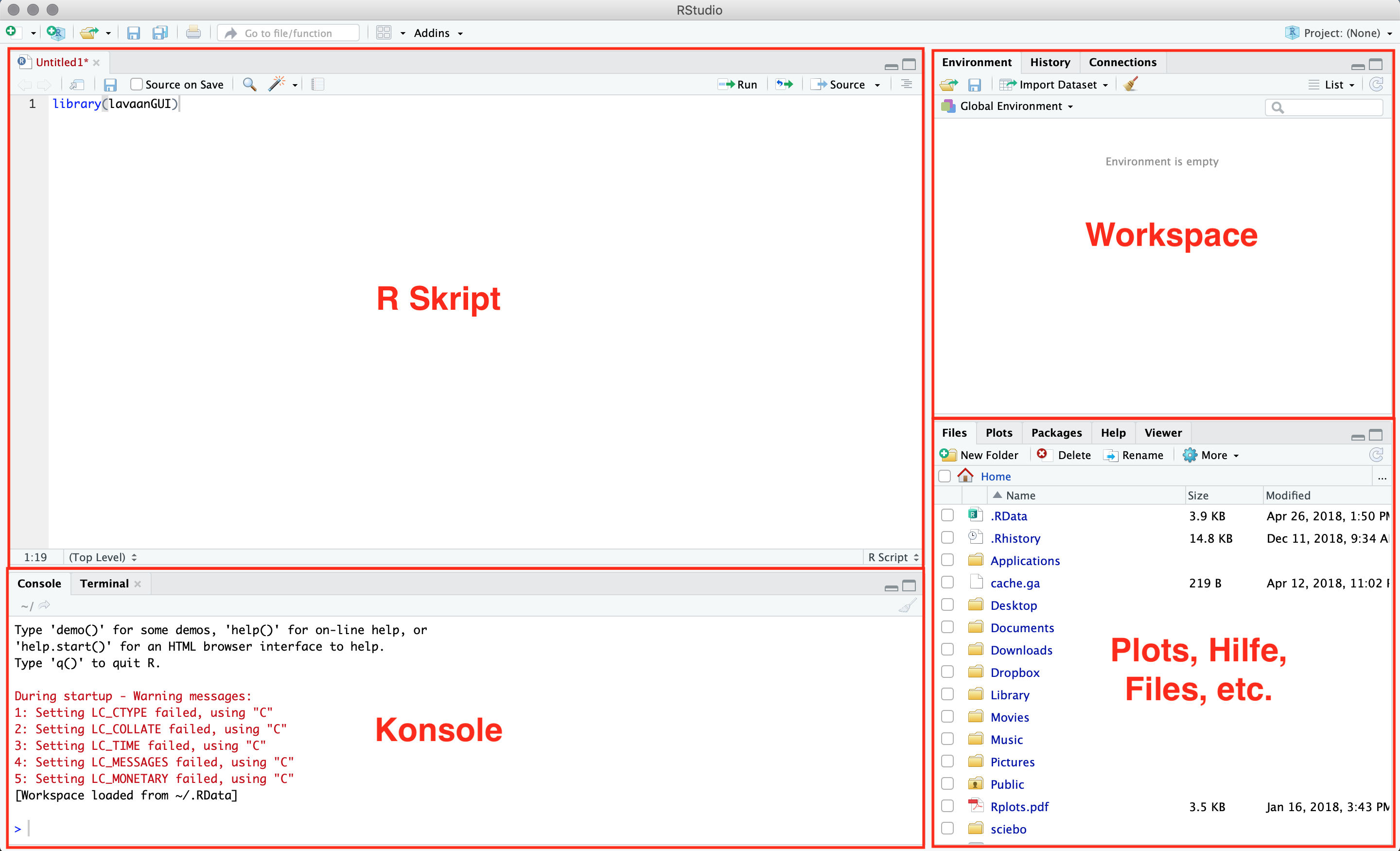
Figure 3.1: RStudio
Auf der linken Seite oben befindet sich das Skript, darunter die Konsole. Oben rechts ist der Workspace und unten rechts das Fenster für Plots, Hilfe, Files und mehr. Im Skript gibt man die Befehle ein, die R ausführen soll. Das Skript kann gespeichert werden, wodurch die Befehle gesichert werden können.
R unterscheidet sich dadurch von SPSS, als dass R syntaxbasiert ist. Dies bedeutet, dass es in R keine Möglichkeit gibt, über verschiedene Schaltflächen und Menüs die Rechnungen auszuwählen. Stattdessen ist es notwendig, in das R Skript eine Syntax zu schreiben. Diese Syntax besteht aus Befehlen, die die Rechnungen definieren, wie wir es in Kapitel 2.2 getan haben.
In der Konsole werden die Ergebnisse, der im Skript definierten Rechnungen, angezeigt. Gib beispielsweise in das R Skript den Befehl
ein und führe diesen aus. In der Konsole sollte nun das Ergebnis angezeigt werden. Auch in die Konsole können direkt Befehle eingegeben werden. Die Konsole kann allerdings nicht gespeichert werden, wodurch diese verloren gehen, sobald RStudio geschlossen wird. Es beispielsweise ratsam, kleinere Berechnungen in der Konsole durchzuführen (also R als Taschenrechner zu verwenden), damit diese nicht das Skript zu unübersichtlich machen. Probiere dies doch ebenfalls mal aus, und gib den Befehl
in die Konsole ein und führe diesen aus. Um in der Konsole einen Befehl auszuführen, ist es ausreichend die Eingabetaste (um in die nächste Zeile zu kommen) zu verwenden. Die Schaltfläche “Run” ist dafür nicht geeignet, diese wird nur im R Skript verwendet.
Im Workspace werden die eingelesenen Dateien, z.B. Datensätze, angezeigt und auch Listen, die durch R-Befehle erstellt wurden. Auf die Dateien im Workspace kann im Laufe der Berechnungen zurückgegriffen werden. Schreibe beispielsweise die Befehlszeile
in dein R Skript und führe diese aus. Im Workspace erscheint nun ein Eintrag namens “Ergebnis”. Hinter der Bezeichnung des Wertes ist das Ergebnis der Berechnung dargestellt. Schließt man RStudio, wird man gefragt, ob man den Workspace speichern möchte. Dies kann hilfreich sein, wenn man beim nächsten Mal öffnen nicht das gesamte Skript erneut ausführen möchte. Dann kann man den Workspace laden und automatisch sind alle Dateien und Ergebnisse, die im Skript erstellt und definiert wurden, vorhanden.
Das Fenster unten rechts hat mehrere Funktionen. Hier werden beispielsweise alle installierten Pakete angezeigt und durch anwählen der weißen Quadrate vor dem Namen der Pakete können diese geladen werden (entspricht dem library() Befehl aus Kapitel 2). Unter “Help” befinden sich die Hilfedateien zu den einzelnen Paketen, wo man deren genaue Verwendung und die einzelnen Befehlselemente nachlesen kann. Unter “Plots” werden die Grafiken angezeigt, die im Skript definiert werden. Diese kann man hier auch in verschiedenen Formaten speichern.
3.1 Mathematische Operatoren, R als Taschenrechner und logische Abfragen
Um R verwenden zu können, ist es wichtig die grundlegendsten logischen Operatoren und Rechensymbole zu kennen, die bei der Definition von Abfragen und Rechnungen angewandt werden. Die logischen Operatoren sind die Folgenden:
| Operator | Bedeutung |
|---|---|
| == | gleich |
| != | ungleich |
| > | größer |
| < | kleiner |
| >= | größer gleich |
| <= | kleiner gleich |
Logische Operatoren dienen dazu, logische Abfragen durchzuführen. Dabei wird getestet, ob die rechte und linke Seite des logischen Operators gleich/ungleich/größer/kleiner/etc. sind. Die logischen Abfragen werden in diesem Tutorial in grau hinterlegten Kästen dargestellt, die Ergebnisse jeweils direkt darunter, gekennzeichnet durch die doppelte Raute. Bei logischen Abfragen ist das Ergebnis keine Zahl, sondern “true” oder “false”, was darstellt, ob die logische Abfrage, so wie sie in der Befehlszeile definiert wurde, richtig oder falsch ist.
## [1] TRUE## [1] FALSEIm ersten Beispiel lautet die Antwort “true”, da der logische Operator besagt, dass die rechte und linke Seite gleich sein sollen. Dies trifft auf “5” und “2+3” zu, daher ist die Abfrage korrekt. Im zweiten Beispiel wurde definiert, dass die beiden Seiten des ungleich Operators verschieden voneinander sind. Dies trifft auf “7” und “14/2” (14 geteilt durch 2) nicht zu, weswegen die Antwort “false” lautet. Diese Abfrage ist also falsch. Probiere einmal aus, eine solche Abfrage selbst in RStudio zu definieren. Ersetze beispielsweise den ungleich Operator des zweiten Beispiels durch den, der die Antwort “true” hervorbringen würde.
R und RStudio können auch als Taschenrechner verwendet werden. Dafür werden die folgenden mathematischen Zeichen verwendet:
| Symbol | Bedeutung |
|---|---|
| + | Addition |
| - | Subtraktion |
* |
Multiplikation |
| / | Division |
| ^ | Potenz |
| sqrt(x) | Quadratwurzel |
Für Berechnungen mit den oben genannten Rechenzeichen werden Ergebnisse ausgegeben. Die Rechenbefehle werden wie auch die logischen Abfragen in grauen Kästen in diesem Tutorial dargestellt, die Ergebnisse darunter durch die doppelte Raute gekennzeichnet.
## [1] 7## [1] 3## [1] 2## [1] 8Probiere es einmal selbst aus, Berechnungen und logische Abfragen zu definieren. Verwende dafür sowohl das R Skript als auch die Konsole.
3.2 Aufbau von R Befehlen
In R gibt es verschiedene Arten von Befehlen. Die einfachsten sind Rechensymbole wie das Additions- (+), Subtraktions- (-) oder Multiplikationszeichen (*). Wie in 3.1 dargestellt, können diese zur Berechnung einfacher und komplexerer Rechnungen herangezogen werden. Für diese Befehle sind keine weiteren Informationen oder Argumente notwendig. Die nächste Stufe an Befehlen sind solche, denen weitere Informationen hinzugefügt werden können oder die diese sogar benötigen, um korrekt ausgeführt zu werden. Ein Beispiel für einen solchen Befehl ist der Logarithmusbefehl log(). Der Logarithmusbefehl kann für eine Zahl ohne die Definition weiterer Argumente verwendet werden.
## [1] 1.609438Der Befehl lässt es aber auch zu, dass die Basis als weiteres Argument definiert wird.
## [1] 0.69897## [1] 1.609438An den Ergebnissen der Berechnung mit definierter Basis ist ersichtlich, dass die Grundeinstellung des Befehls die Berechnung des Logarithmus auf Basis der eulerschen Zahl e ist. Soll der Logarithmus mit einer anderen Basis berechnet werden, kann dies durch das Argument “base = x” innerhalb des Befehls, hinter der Zahl, deren Logarithmus berechnet werden soll und durch ein Komma davon abgetrennt, definiert werden. Dieses zusätzliche Argument ist, wie dargestellt, ein möglicher Zusatz, aber keine notwendige Voraussetzung zur Ausführung des Befehls.
Dieses Prinzip der Möglichkeit aber keiner Notwendigkeit, besteht bei vielen R-Befehlen. Vor allem bei den Befehlen, die mehr als nur ein Argument besitzen, das definiert werden kann. Ein Beispiel für einen solchen Befehl wird im folgenden Kapitel 3.3 dargestellt.
3.3 Daten einlesen
Um Daten in R verwenden und auswerten zu können muss die Datei, in der die Daten gespeichert sind, in R eingelesen werden. Um einen Datensatz in R einzulesen gibt es verschiedene Vorgehensweisen. Entweder man kann ihn über das Menü einlesen, oder per Hand. Zuerst wird im Folgenden erläutert, wie das Einlesen über das Menü funktioniert. Anschließend wird ausführlich dargestellt, wie in R Daten per Hand über unterschiedliche Einlesebefehle für verschiedene Datenformate eingelesen werden.
3.3.1 Daten über das Menü einlesen
Um einen Datensatz über das RStudio Menü einzulesen, muss das Menü “File” der Menüleiste angeklickt werden. Dort befindet sich die Schaltfläche “Import Dataset”.
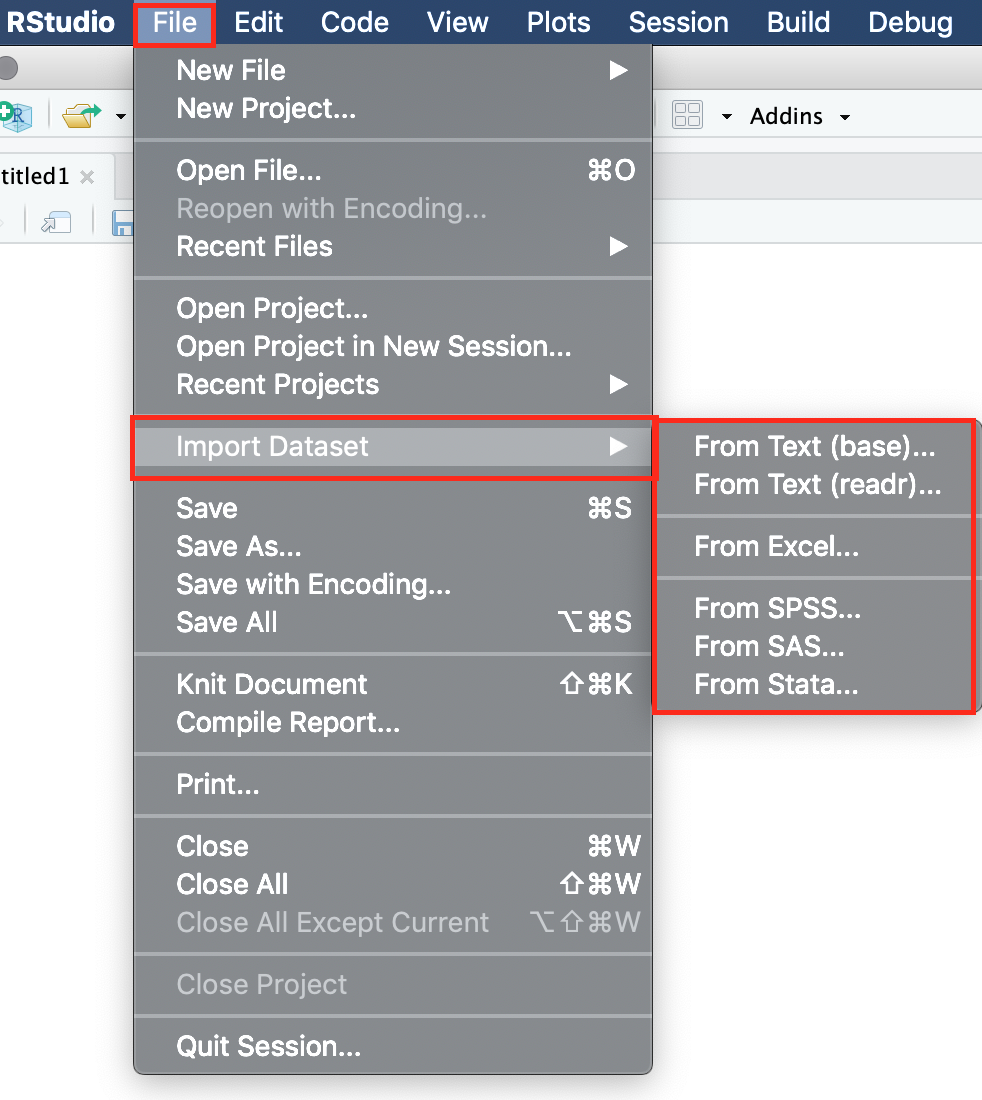
Figure 3.2: File - Import Dataset
Im sich daraufhin öffnenden Klappmenü bestehen verschiedene Möglichkeiten für die unterschiedlichen Datenformate. Um eine SPSS Datei einzulesen ist das Menü “From SPSS” geeignet, für Exceldateien “From Excel” und für csv-Dateien “From Text (readr)”. Nach der Auswahl eines der Menüs öffnet sich ein neues Fenster (je nach gewählter Quelle (SPSS, Excel, csv) kann dies unterschiedlich aussehen, hat aber immer die gleiche Funktion):
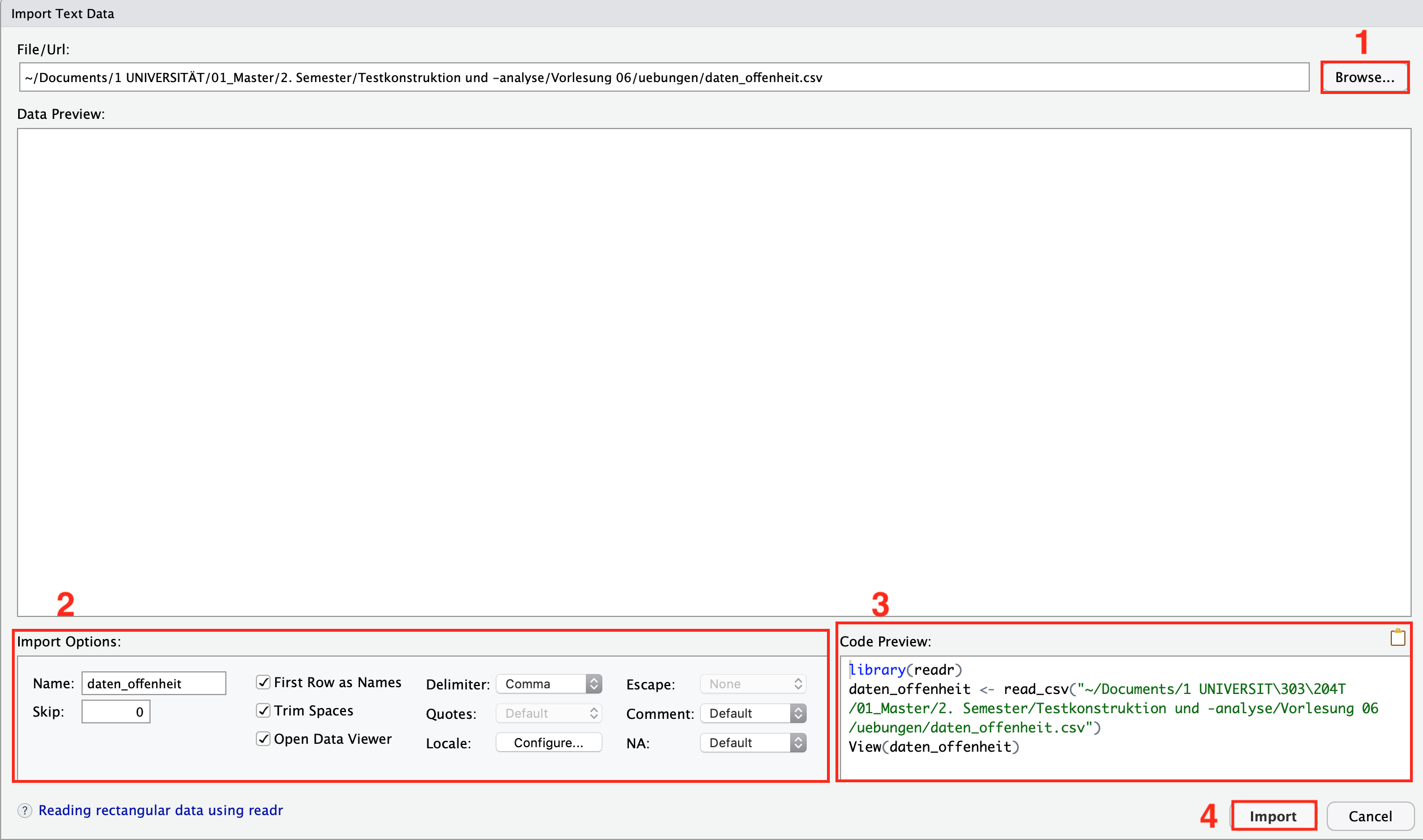
Figure 3.3: Import Dataset - Daten auswählen
Um den Datensatz auszuwählen, klickt man die Schaltfläche “Browse” (im Bild durch die Zahl “1” gekennzeichnet) an. Daraufhin öffnet sich ein neues Fenster, in dem der Speicherort der Daten auf dem PC ausgewählt und bestätigt wird. Der Dateipfad der Datendatei erscheint in dem Feld links neben der Browseschaltfläche. Unter dem Feld “Import Options” (im Bild durch die Zahl “2” gekennzeichnet) kann festgelegt werden, wie der Datensatz heißen soll (Name), ob die erste Reihe der Daten die Spaltennamen enthält (Häkchen bei “First Row as Names”) oder welches Zellentrennzeichen verwendet wurde (Delimiter). Sollten die Daten nicht korrekt eingelesen werden, lohnt es sich im ersten Schritt der Problembehebung an dieser Stelle die Einstellungen zu verändern.
Im Feld “Code Preview” (im Bild durch die Zahl “3” gekennzeichnet) unten rechts erscheint der Code, der in das R Skript geschrieben werden müsste, um die Daten auf die Art und Weise einzulesen. Da beim Einlesen über das Menü die Codezeile nicht automatisch in die R Syntax geschrieben wird, sollte der Einlesebefehl aus dem Feld “Code Preview” in die R-Syntax kopiert werden. Dies ist hilfreich, da dieser beim nächste Öffnen der Syntax nur noch ausgeführt werden muss, um die Daten einzulesen. Dadurch spart man sich den Umweg über das Menü.
Um die Daten letztendlich einzulesen, muss die Schaltfläche “Import” (im Bild durch die Zahl “4” gekennzeichnet) ausgeführt werden. Ist im Feld “Import Options” die Auswahl “Open Data Viewer” ausgewählt, öffnet sich daraufhin die Datenansicht in RStudio. Außerdem wird der Datensatz nun unter dem gewählten Namen im RStudio Workspace angezeigt.
3.3.2 Daten per Hand einlesen
Um den manuellen Einleseprozess zu erleichtern, kann das Arbeitsverzeichnis auf dem PC, in dem das R-Skript gespeichert werden soll, im Vorhinein festgelegt werden. Das führt dazu, dass im Einlesebefehl der Daten nicht mehr der gesamte Dateipfad verwendet werden muss. Stattdessen reicht es aus den Dateinamen zu verwenden. Dieses Vorgehen wurde in Kapitel 3.3.1 verwendet, weswegen im dortigen Code der gesamte Dateipfad verwendet wurde. Wir hatten vorher kein Arbeitsverzeichnis erstellt.
Da es aber sehr hilfreich ist ein Arbeitsverzeichnis (Working directory) zu definieren, zeigen wir euch im Folgenden, wie man dies bewerkstelligt.
Um das Arbeitsverzeichnis zu bestimmen schreibt man in das Skript den folgenden Befehl:
Der Pfad zum Arbeitsverzeichnis kann beispielsweise so aussehen:
Dieser Pfad ist auf jedem Computer individuell und muss für jedes neue Projekt bzw. jedes neue Skript erneut festgelegt werden. Es ist wichtig darauf zu achten, dass der gesamte Pfad des Arbeitsverzeichnisses angegeben wird.
Eine einfachere Methode ist es, über die Menüzeile des Programms das Arbeitsverzeichnis auszuwählen. Dazu geht man wie folgt vor: In der Menüzeile von RStudio wählt man das Menü “Session” aus. Innerhalb dieses Menüs das Untermenü “Set Working Directory”, und darin das Untermeü “Choose Directory”.

Figure 3.4: Arbeitsverzeichnis festlegen- Menü
Daraufhin öffnet sich ein neues Fenster über das der Speicherort der Daten auf dem PC ausgewählt werden kann. Dieser wird über den Button “open” ausgewählt. Der Befehl wird dann in der Konsole angegeben und kann von dort aus in das Skript kopiert werden. (Es ist sinnvoll den Befehl in das Skript zu kopieren, damit auch dieser beim erneuten Aufrufen des Skripts sofort ausgeführt werden kann, ohne den langen Weg über das Menü verwenden zu müssen.)
Um R zu fragen, welches Arbeitsverzeichnis es im Moment verwendet, führt man folgenden Befehl aus:
Daraufhin wird in der Konsole der Pfad des aktuellen Arbeitsverzechnisses angezeigt.
Hat man das Arbeitsverzeichnis im Vorhinein festgelegt, und liegen in diesem Verzeichnis auch die Daten, die eingelesen werden sollen, muss man beim Einlesebefehl nicht mehr das gesamte Verzeichnis angeben. Es reicht nun, wenn man den Namen der Datei inklusive Dateiendung angibt.
Hat man das Arbeitsverzeichnis im Vorhinen nicht festgelegt oder die Daten in einem anderen Verzeichnis gespeichert, ist es notwendig den gesamten Dateipfad im Einlesebefehl zu verwenden:
Der Befehl read.table wird für Datensätze im csv- oder Textdateiformat verwendet. Möchte man lieber Befehle mit Voreinstellungen nutzen, stehen für das csv-Datenformat auch die Befehle read.csv und read.csv2 zur Verfügung. Dieser werden in 3.3.3 und 3.3.4 näher vorgestellt.
Der Befehl read.table() (und entsprechend auch die anderen genannten Befehle) ist einer der R Befehle, wie in Kapitel @ref (AufbauRBefehl) vorgestellt, der mehrere Argumente haben kann. Keins der Argumente des Befehls read.table() ist notwendig, aber alle sind möglich. Die wichtigsten Argumente sind:
| Parameter | Bedeutung |
|---|---|
| file | Hier wird der Name der Datendatei, die eingelesen werden soll, in doppelte Anführungszeichen ("") geschrieben. Jede Zeile der Datendatei wird eine eigene Zeile der Tabelle in R und jede Spalte, eine eigene Spalte. |
| header | In Datendateien enthält die erste Zeile oftmals die Spaltennamen, also die Überschriften (Header) der jeweiligen Spalte. Um dies R mitzuteilen und somit zu verhindern, dass R die erste Zeile als normale “Daten” bearbeitet, schreibt man in den Einlesebefehl header = TRUE |
| sep | Definition des Datenfeldtrennzeichens (Zeichen, mit denen die verschiedenen Werte auseinander gehalten werden). Oftmals werden dafür Tabulatoren, Kommata oder Punkte verwendet, je nach Datenformat. Damit die Tabelle auch in R korrekt dargestellt wird, muss man R mitteilen, welches Zeichen verwendet wurde. Das Zeichen wird ebenfalls immer in doppelte Anführungszeichen dargestellt und hinter ein Gleichheitszeichen geschrieben: sep = |
| sep = | "\t" (Tabulator |
| sep = | “,” (Komma) |
| sep = | “.” (Punkt) |
| dec | Definition des Dezimaltrennzeichens. Das Dezimaltrennzeichen, das verwendet wurde wird ebenfalls immer in doppelte Anführungszeichen hinter einem Gleichheitszeichen aufgeführt: dec = |
| dec = | “.” (Punkt) |
| dec = | “,” (Komma) |
| na | Fehlende Werte müssen nicht extra kodiert werden. Im csv Format wird eine leere Zelle automatisch erkannt, mit zwei Kommata gefüllt und von R als NA eingelesen. Sollten fehlende Werte anders kodiert worden sein, wird auch dies hinter dem Befehl na = in doppelten Anführungszeichen in den Einlesebefehl geschrieben. |
Wichtig zu nennen ist im Zusammenhang des Dateneinlesens, dass R auf die Groß- und Kleinschreibung achtet. Verwendet man also die falsche Schreibweise im Befehl, erhält man eine Fehlermeldung und die Daten können nicht eingelesen werden.
Um den Datensatz “Bsp.Datensatz” also korrekt einzulesen, lautet die entsprechende Befehlszeile:
read.table(file = "~/Documents/1 UNIVERSITÄT/01_Master/2. Semester/
Testkonstruktion und -analyse/Vorlesung 06/uebungen/
daten_offenheit.csv", header = TRUE, sep = ",", dec = ".")Für diesen Datensatz wurde definiert, dass der Datensatz unter dem angegebenen Speicherort zu finden ist, die erste Zeile die Spaltennamen beinhaltet, das Spaltentrennzeichen das Komma und das Dezimaltrennzeichen der Punkt ist.
3.3.3 read.csv
Ist bekannt, welche Zell- und Dezimaltrennzeichen verwendet wurden, können Befehle mit Voreinstellungen verwendet werden. Dazu zählen die hier näher erläuterten Befehle “read.csv” und “read.csv2”.
Die Defaulteinstellungen des Befehls read.csv sind die Folgenden:
- header = TRUE
- sep = “,” (Komma als Zelltrennzeichen)
- dec = “.” (Punkt als Dezimaltrennzeichen)
Um einen Datensatz mit den entsprechenden Eigenschaften einzulesen reicht dementsprechend die folgende Befehlszeile:
read.csv(file = "~/Documents/1 UNIVERSIT\303\204T/01_Master/2. Semester/
Testkonstruktion und -analyse/Vorlesung 06/uebungen/daten_offenheit.csv")Damit das Einlesen des Datensatzes problemlos funktioniert, muss die erste Zeile die Spaltennamen enthalten, das Spaltentrennzeichen das Komma und das Dezimaltrennzeichen der Punkt sein.
3.3.4 read.csv2
Die Defaulteinstellungen des Befehls read.csv2 sind die Folgenden:
- header = TRUE
- sep = “;” (Semikolon als Zelltrennzeichen)
- dec = “,” (Komma als Dezimaltrennzeichen)
Für einen Datensatz, der über den read.csv2 Befehl problemlos eingelesen werden kann gilt, dass die erste Zeile wiederum die Spaltennamen enthält. Das Spaltentrennzeichen ist allerdings das Semikolon, das Dezimaltrennzeichen wieder der Punkt. Der entsprechende Befehl sähe folgendermaßen aus:
3.3.5 Trouble shooting: Mein Datensatz hat in R nur eine Spalte
Hat man beim Einlesen einen Fehler gemacht und das Spaltentrennzeichen falsch definiert, zeigt RStudio den Datensatz inkorrekt an. Er besteht dann aus mehreren Zeilen aber nur einer Spalte. RStudio hat nicht korrekt erkannt, dass der Datensatz mehrere Spalten hat, da es nicht gesagt korrekt vermittelt bekommen hat, woran es einzelne Spalten erkennt. Dies erkennt man am eingelesenen Datensatz im Workspace, wenn der Eintrag beispielsweise so aussieht:

Figure 3.5: Inkorrekt eingelesener Datensatz
Behoben werden kann der Fehler einfach, in dem das Spaltentrennzeichen im Einlesebefehl der Daten (sep = ) verändert wird. Weiß man nicht, welches Trennzeichen bei der Erstellung der Datendatei verwendet wurde, probiert man am besten alle einmal aus, bis der Datensatz im Workspace so viele Variablen anzeigt, wie der ursprüngliche Datensatz Spalten hat. Alternativ kann man in den Metadaten der ursprünglichen Datei nachschauen.
3.3.6 read.spss
Es ist auch möglich Daten im SPSS-Format (.sav) einzulesen und weiterzuverarbeiten. Um dies tun zu können, muss zunächst das Paket “foreign” installiert und geladen werden:
Zusätzlich muss das aktuelle Arbeitsverzeichnis dem Ordner entsprechen, in dem die Daten gespeichert sind (siehe 3.3). Um die Daten einzulesen wird der folgende Befehl verwendet:
Innerhalb der Anführungszeichen steht der Dateiname. Das hintenstehende Argument (to.data.frame=TRUE) left fest, dass die eingelesenen Daten in eine Tabelle, einen so genannten Data Frame, formatiert werden. Da SPSS das Speicherformat leicht verändert, kann es zu Fehlermeldungen kommen. Die Datei sollte trotzdem korrekt eingelesen werden.
Um SPSS-Daten einzulesen gibt es noch eine weitere Option, die das Hmisc-Paket verwendet:
3.3.7 Warum kann lavaanGUI manchmal die Daten nicht richtig einlesen und darstellen?
Ihr werdet (eventuell) den Fall haben, dass lavaanGUI euren Datensatz zwar einliest, aber in der Darstellung eure Daten nicht so aussehen, wie ihr sie abgespeichert habt. Das liegt dann (sehr wahrscheinlich) an den Defaulteinstellungen, die lavaanGUI im Hintergrund trifft. Wie weiter unten beschrieben, könnt ihr diese ändern. Um eure Daten richtig darzustellen habt ihr die Möglichkeit die verschiedenen Optionen für z.B. Dezimal- und Zellentrennzeichen auszuprobieren, oder ihr schaut in den Metadaten eurer Datendatei nach, welche Einstellungen dort getroffen wurden. Wenn ihr diese Einstellungen in lavaanGUI übernehmt, sollten auch dort die Daten korrekt eingelesen und dargestellt werden.
3.4 Objekte erstellen
Hat man die Daten nur eingelesen, werden die Daten einmal in der Konsole dargestellt. Sie werden dort aber nicht gespeichert so dass man mit ihnen arbeiten kann. Dazu muss man ihnen einen Namen zuweisen, bzw. einem sogenannten Objekt. Dies hat immer die Form:
Objektname <- Befehl
Hinter dem Pfeil steht der Befehl, der die Daten betrifft. Dies kann z.B. der read.table Befehl sein, aber auch ein anderer, der sich nur auf einzelne Variablen bezieht. Das Wichtige ist der Pfeil (<-).
Der Objektname kann beliebig gewählt werden. Dabei ist zu beachten, dass R zwischen Groß- und Kleinschreibung unterscheidet!
Eine Objektzuweisung um Daten einzulesen kann beispielsweise folgendermaßen aussehen:
Nun erscheint rechts im Workspace der Datensatz unter dem Namen “data”. Klickt man das kleine Tabellensymbol am rechten Ende der Zeile an, öffnet sich ein neuer R-tab, in dem die Daten in Tabellenform angezeigt werden. So kann auch überprüft werden, ob die Daten richtig eingelesen wurden, ob also z.B. die richtigen Dezimal- und Zellentrennzeichen verwendet wurden.
Die Unterscheidung zwischen Groß- und Kleinschreibung wird am folgenden Syntaybeispiel gezeigt. Der Datensatz wurde unter dem Objektnamen “data” gespeichert. Möchte man nun den Minimalwert der Variable y1 des Datensatzes berechnen, kann folgende Syntaxzeile verwendet werden:
Wird diese ausgeführt, wird in der Konsole das entsprechende Ergebnis angezeigt. Hat man allerdings in der Syntax einen Schreibfehler gemacht, und den Datensatz durch die Bezeichnung “Data” angesprochen (siehe nachfolgende Syntaxzeile) wird in der Konsole die nachfolgende Fehlermeldung angezeigt:
Ein häufiger Grund dafür, dass ein Objekt, auf das ihr euch in eurer Syntax bezieht, nicht gefunden wird, liegt in Fehlern der Groß- und Kleinschreibung von Objektnamen.
3.5 Kommentare einfügen
Zur besseren Nachvollziehbarkeit oder Erklärung, oder wenn man mit mehreren Personen an einem Dokument arbeitet, kann es sinnvoll sein, die Syntax im R Skript auszukommentieren. Um R klar zu machen, dass das, was man schreibt ein Kommentar ist, und von R nicht berücksichtigt werden soll, verwendet man die Raute #. Alles was hinter diesem Zeichen steht wird von R ignoriert. Man kann sowohl ganze Zeilen damit auskommentieren, oder auch in einer Zeile, in der ein Befehl geschrieben steht, dahinter einen Kommentar einfügen, selbst wenn der Befehl in der nächsten Zeile weitergeht. Kommentare werden immer in der Schriftfarbe grün dargestellt.
Möchte man mehrere Zeilen auf einmal auskommentieren (beispielsweise bei einer Ergebnisdarstellung, die über mehrere Zeilen geht), kann man dies ebenfalls über die Menüzeile von RStudio machen. Dafür markiert man mit der Maus alle Zeilen, die kommentiert werden sollen, und verwendet dann: Code - Comment/Uncomment Lines. Auf diese Art und Weise kann man auch mehrere Zeilen, die man vorher auskommentiert hat, wieder entkommentieren. Die Raute vor jeder Zeile verschwindet dann wieder, die Schriftfarbe wird wieder schwarz und R führt die Zeilen aus.
3.6 Einzelne Variablen ansprechen
Nicht immer möchte man einen ganzen Datensatz ansprechen. Manchmal möchte man sich auch nur auf einzelne Variablen beziehen. Diese kann man entweder gemeinsam in einem neuen Objekt speichern, oder einen Befehl auch nur auf einzelne Variablen anwenden. Dazu wird das Dollarzeichen ($) verwendet. Vor das Dollarzeichen (auf die linke Seite) schreibt man den Namen des Datensatzes, aus dem man die Variable auswählen möchte, auf die rechte Seite (also hinter das Dollarzeichen) schreibt man den Variablennamen. Das sieht dann beispielsweise so aus:
Wären diese Befehle aus unserem R-Skript würde beim Ausführen der Befehle ein zweites Objekt (Objekt2) im Workspace auftauchen, das nur aus den Variablen bestünde, die wir im Befehl mit den Dollarzeichen angesprochen haben. Für den zweiten Befehl erhielten wir ein Ergebnis in der Konsole, nämlich den Minimalwert der Variable1 aus dem Datensatz “data”.
3.7 Die summary Funktion
Der summary Befehl ist ein nützlicher und häufig verwendeter Befehl. Er kann beispielsweise in der deskriptiven Itembeschreibung verwendet werden. Wendet man ihn auf einzelne Variablen oder einen Datensatz an, gibt er entweder für diese Variable oder alle Variablen des Datensatzes das jeweilige Minimum, 1. Quantil, den Median, den Mittelwert (mean), das 3. Quantil und das jeweilige Maximum an. Verwendet wird er so:
Oder für einzelne Variablen:
Ein Output sieht dann folgendermaßen aus:
Auch andere Pakete greifen auf den Befehl zurück, darunter auch das lavaan Paket. Näheres dazu in späteren Kapiteln (9.2, 9.3, 9.4, 12.5).